
In september reisden Tom en Reinout af naar Berlijn om de SMX Advanced Europe conferentie bij te wonen. Daar deden zij meer kennis op over de nieuwste trends op het gebied van PPC en SEO. Het evenement was niet alleen een bron van waardevolle kennis, maar bood ook uitstekende kansen voor netwerken. In deze blogpost belichten we enkele van de belangrijkste inzichten en ervaringen die Tom en Reinout tijdens dit evenement hebben opgedaan
Entities are the past: Search is going multidimensional
– Tom Anthony
Het uitgangspunt van deze sessie lag voornamelijk bij de impact van de opkomst van AI op hoe Google websites leest. Er vindt namelijk een verschuiving plaats van keywords naar entiteiten. Terwijl keywords de traditionele methode waren waarmee zoekmachines content interpreteerden, bieden entiteiten een dieper inzicht in de betekenis en context van content. Dankzij het gebruik van LLM’s (Large Language Models) kan Google de content op websites niet alleen beter begrijpen, maar ook verbanden leggen tussen de verschillende informatie op een website en de zoekintentie van een zoekopdracht.
Als voorbeeld haalde Tom aan dat het momenteel onmogelijk is om een product, zoals een kinderzwembad, via product structured data van schema.org als ‘kindvriendelijk’ te labelen. Echter, een LLM kan uit een productbeschrijving als ‘Het zwembad, omgeven door een afsluitbaar veiligheidshek, heeft een diepte van 60 cm tot 240 cm,’ moeiteloos concluderen dat het zwembad een geschikt resultaat is voor de zoekopdracht ‘kindvriendelijk zwembad’. Waar structured data deze link niet kan leggen, kan een LLM dit wel.
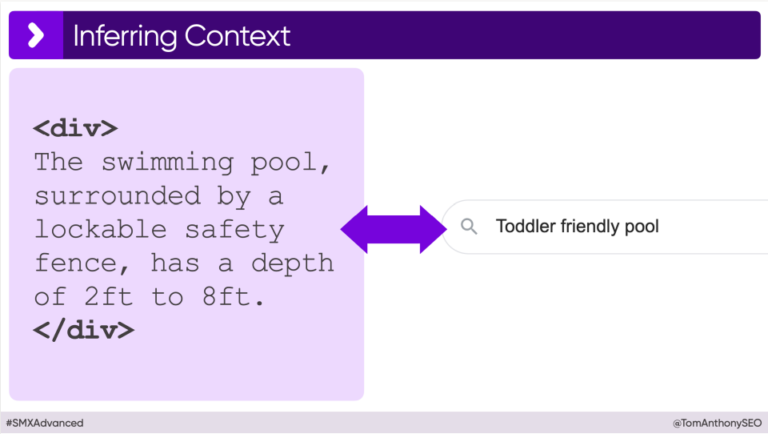
De focus verschuift dus naar context-rijke pagina’s. Google test momenteel het toevoegen van knoppen bij de zoekbalk om zoekopdrachten te specificeren. Hierdoor komt de nadruk steeds meer te liggen op longtail keywords, omdat er steeds specifieker gezocht wordt en er dus ook steeds specifiekere content gevraagd wordt.
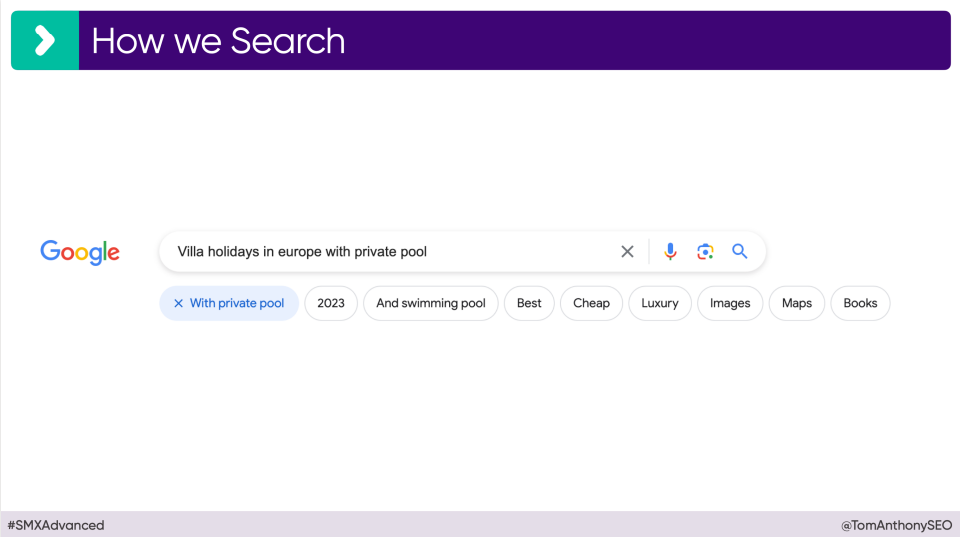
Als afsluiting deelde Tom zijn visie op de toekomst van SEO. Hij benadrukt dat met de opkomst van LLM’s, het belang van structured data afneemt en de nadruk meer zal liggen op context-rijke content op webpagina’s, wat ook blijkt uit de verschillende content updates van Google.
Belangrijkste learnings van de presentatie:
- Het belang van longtail keywords neemt toe in zoekwoordstrategieën.
- Het gebruik van structured data markup wordt op de lange termijn minder belangrijk.
- Het integreren van context-rijke content wordt steeds essentiëler.
- De nadruk op E.E.A.T. (Experience, Expertise, Authoritativeness, Trustworthiness) neemt toe
Advanced tactics for using AI tools & big data analysis to improve EEAT
– Lily Ray
Wanneer je zoekt naar manieren om je content en website te optimaliseren, is het gebruik van AI-tools onmisbaar geworden. Toch wordt vaak meer gefocust op de kwantiteit die AI oplevert dan op de kwaliteit die het kan bieden. Lily Ray deelde tijdens haar presentatie een reeks inzichten en praktische tips over hoe je AI het beste kunt inzetten om de kwaliteit van je online content te verbeteren
Wat zijn de risico’s van het gebruik van AI
AI is zeer bekwaam in het uitvoeren van bepaalde taken, maar wordt soms ook ingezet voor taken die beter door mensen uitgevoerd kunnen worden. Dit kan diverse problemen veroorzaken:
- Content die onjuiste informatie bevat.
- Problemen met auteursrechten.
- Cybersecurity-uitdagingen.
- Content die gebaseerd is op verouderde data (bijvoorbeeld, ChatGPT beschikt over een database die enkel informatie bevat tot en met september 2021)

Waar kun je AI juist wel voor gebruiken?
Naast de risico’s van het gebruik van AI gaf Lily een aantal praktische voorbeelden waar AI juist wel voor gebruikt kan worden. Zo werd er voor SEO specialisten juist aangemoedigd om de volgende taken door AI uit te laten voeren:
1. Content Analyse
Een van de voorbeelden die Lily in haar presentatie aanhaalde, betrof het gebruik van de ChatGPT-plugin WebPilot. Hiermee analyseerde ze meerdere URL’s om inzicht te verkrijgen in de verschillen in content, en om te bepalen waar verbeteringen mogelijk zijn ten opzichte van concurrenten. Na de analyse van de content stelde ze vragen zoals:
- Welke inhoud is aanwezig op pagina A maar niet op pagina B? (informatiewinst)
- Bevatten de pagina’s verschillende niveaus van ervaring, expertise, autoriteit en betrouwbaarheid (E.E.A.T.)? Zo ja, waarom?
- Hoe kan pagina A verbeterd worden om uitgebreidere informatie te bieden dan pagina B?
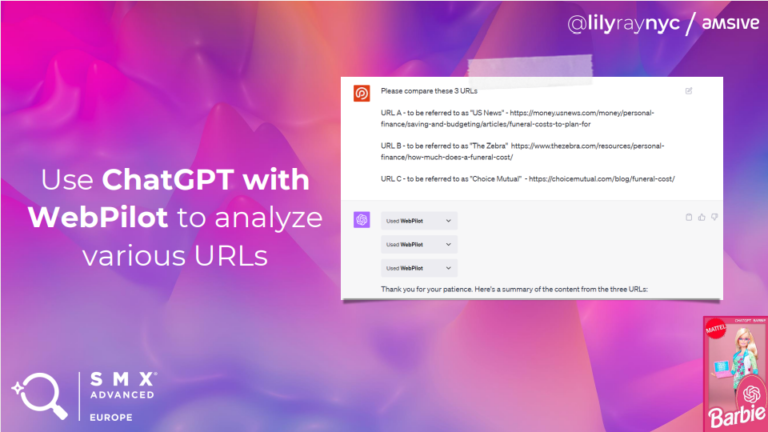
Bovendien is het mogelijk om je website te vergelijken met de Google-richtlijnen of recente updates. ChatGPT kan deze informatie analyseren en inzichten bieden over waar je content niet voldoet aan de Google-richtlijnen en hoe deze verbeterd kan worden.
2. Data Analyse
Met de Advanced Data Analysis-functie binnen ChatGPT is het mogelijk om grote hoeveelheden data te analyseren en daaruit conclusies te trekken. Lily gaf als voorbeeld hoe Search Console-data geanalyseerd kan worden om het aantal klikken en impressies per subgroep te clusteren. Hierdoor wordt snel duidelijk welke subgroepen de meeste klikken en vertoningen genereren.
De volgende stap is het visualiseren van deze data. Dankzij de Diagrams show me-plugin binnen ChatGPT kunnen de geanalyseerde gegevens visueel worden weergegeven. Dit maakt niet alleen het analyseren eenvoudiger, maar helpt ook om de resultaten duidelijker aan klanten te presenteren.
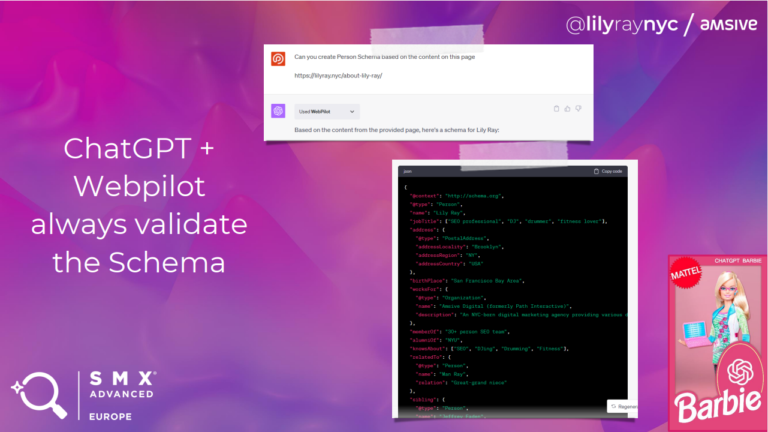
3. Genereren van Schema gebaseerd op de content van je pagina
De Webpilot-plugin van ChatGPT maakt het mogelijk om structured data automatisch te genereren. Webpilot analyseert de bestaande informatie op je website en creëert daarvoor passende structured data. Lily illustreerde dit met een voorbeeld waarbij Person Structured Data gegenereerd werd, enkel op basis van een URL. Dit maakt het genereren van structured data enorm eenvoudig. Het is echter belangrijk om deze automatisch gegenereerde data altijd nog eens te controleren voordat je het online publiceert.
Belangrijkste learnings van de presentatie:
Het aanbevolen gebruik van AI voor SEO:
- Content Analyse: Gebruik AI om content op verschillende URL’s te vergelijken en te verbeteren, en beoordeel aspecten zoals ervaring, expertise, autoriteit en betrouwbaarheid (E.E.A.T.).
- Data Analyse: Zet AI in voor het analyseren van grote datavolumes, zoals data uit de Search Console, om inzichten te verkrijgen over klikken en vertoningen. Gebruik vervolgens tools om deze data visueel te maken.
- Genereren van Schema Structured Data: Benut AI voor het creëren van structured data op basis van pagina-inhoud, en zorg voor een grondige validatie voordat je deze publiceert.
Is there such a thing as too much crawling?
– Joost de Valk
Joost de Valk, bekend van zijn Yoast-plugin en een autoriteit binnen de SEO-wereld, sloot de eerste dag van de conferentie af met een krachtig pleidooi voor milieubescherming. Hij benadrukte de verantwoordelijkheid die SEO-specialisten dragen in dit opzicht. Volgens hem zal het internet tegen 2025 verantwoordelijk zijn voor een vijfde van het wereldwijde elektriciteitsverbruik. Verder citeerde hij berekeningen van Cloudflare’s Radar, die aangeven dat 28% van het webverkeer uit botverkeer zal bestaan. Dit betekent dat maar liefst 5% van de wereldwijde elektriciteit verbruikt wordt door bots.

Een voorbeeld hiervan
Google crawlt meer dan alleen basis URL’s. Joost illustreerde dit met het voorbeeld van de website van zijn vader. Hoewel deze website op het eerste gezicht slechts uit 5 hoofdpagina’s en 30 blogpagina’s lijkt te bestaan, omvat het in werkelijkheid veel meer. Er zijn namelijk ook 60 tagpagina’s, 5 categoriepagina’s voor de blog, tussen de 30 en 50 datumgerelateerde pagina’s, en ten minste één auteursarchiefpagina. Bovendien heeft elke pagina zijn eigen RSS-feed. Daarnaast bevat de site CSS-bestanden, JavaScript-bestanden, shortlinks, ingebedde URL’s en meer. In totaal heeft deze schijnbaar kleine website van 35 pagina’s eigenlijk meer dan 300 verschillende pagina’s die allemaal door Google worden gecrawld.
Hoe beperken we het crawlen op de website?
Door gebruik te maken van logbestanden kunnen veel bronnen en URL’s worden geïdentificeerd die wel worden opgeroepen, maar niet noodzakelijk zijn. Het is belangrijk om in te grijpen door de productie van deze bronnen te beperken en de toegang van bepaalde bots te beperken. Voor veel websites is het bijvoorbeeld niet relevant dat zoekmachines als Baidu (China) of Seznam (Tsjechië) hun inhoud crawlen. Het beperken van archief pagina’s van datums en auteurs is sinds kort mogelijk in de Yoast plugin.
Diverse oplossingen om het onnodig crawlen door bots en de creatie van extra URL’s te verminderen zijn:
- Schakel auteur- en datumarchieven uit
- Schakel afbeelding-URL’s uit
- Minimaliseer RSS-feed
- Controleer uw logbestanden
- Blokkeer onnodige bots (zoals Baidu en Seznam)
- Bouw snellere websites
Why we need a smarter keyword taxonomy (for localized searches)
– David Mihm
David startte zijn presentatie met verschillende voorbeelden die de variatie in SERP (Search Engine Results Page) resultaten aantonen, afhankelijk van de locatie waar gezocht wordt. Als voorbeeld nam hij het zoekwoord ‘Knie chirurg’, dat gezocht werd in Berlijn, München en Hamburg. Bij elke zoekopdracht verschilde de SERP aanzienlijk. In Berlijn was er geen lokaal pack zichtbaar, in München verscheen het na de eerste drie zoekresultaten, en in Hamburg werd alleen een Google Bedrijfsprofiel getoond. Hij benadrukte echter dat de huidige SEO-tools geen rekening houden met deze verschillende SERP’s.
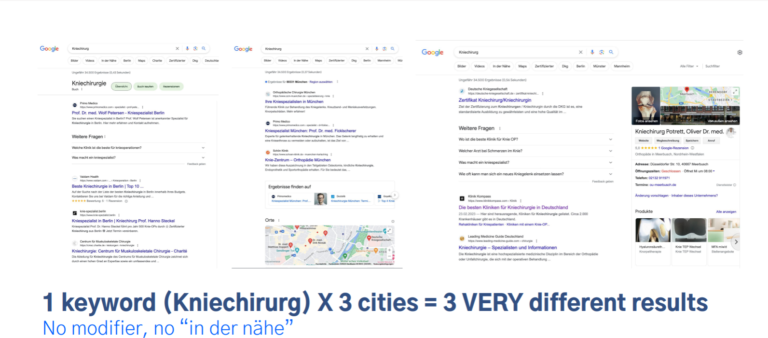
David toonde aan dat het opzetten van een eigen procedure voor SEO loont. Hij onderzoekt onder meer het voorkomen van verschillende domeinen in diverse SERP’s om de concurrentie te analyseren. Hij classificeert domeinen op basis van type en grootte om die SERP’s uit te sluiten waar lokale bedrijven geen kans maken. Ook beoordeelt hij de kansen op een SERP afhankelijk van de positie of aanwezigheid van een Local Pack. Als het Local Pack bovenaan een SERP staat, ligt de focus op het optimaliseren van het Google bedrijfsprofiel. Staat het Local Pack onderaan of ontbreekt het, dan richt hij zich op het verbeteren van de website voor relevante zoektermen.
Voor het berekenen van de potentie van elke lokale zoekterm, heeft hij een scraping methode ontwikkeld die gebruik maakt van pleber.com voor lokale zoekwoorden. Daarna past hij verschillende filters en groeperingen toe om tot een potentieberekening te komen. De volledige instructie en een voorbeeld in een Google Sheet zijn te vinden op zijn website https://www.davidmihm.com/smxberlin.

Belangrijkste learnings van de presentatie:
- Regionale Variatie in SERP Resultaten: Zoekwoorden leveren verschillende SERP resultaten op in verschillende regio’s.
- Data-gedreven Zoekwoordselectie: Analyseer data om te bepalen welke zoekwoorden lokaal het meest interessant zijn om op in te zetten. Dit geldt zowel voor de standaard ‘blue links’ in de zoekresultaten als voor Google Bedrijfsprofielen.
Dealing With User Intent in a Time Where Google Depends on AI
– Jan-Willem Bobbink
Jan-Willem sloot de SMX Advanced conferentie af met een presentatie over het integreren van AI in werkprocessen. Zijn doel was om de traditionele benadering van zoekintentie te verbreden en een realistischer set van zoekintentie-categorieën te ontwikkelen. Hij benadrukte dat AI slechts in beperkte mate de zoekintentie van zoekwoorden kan inschatten.
Gebruikersintentie wordt vaak gereduceerd tot vier basis categorieën: informatief, navigatie, transactioneel, en commercieel onderzoek. Echter, een veelvoorkomend probleem bij het verliezen van zichtbaarheid in zoekmachines is dat Google de zoekopdracht anders interpreteert. Bijvoorbeeld, na een update kan Google de voorkeur geven aan een gids in plaats van een categoriepagina, wat leidt tot een verschuiving in de SERP, ondanks dat de gebruikersintentie binnen de vier standaardcategorieën hetzelfde blijft.
Om dit probleem te omzeilen, stelde Jan-Willem voor om een systeem te ontwikkelen dat zoekopdrachten en resultaten vergelijkt. Dit zou helpen bij het correct toewijzen van het juiste contenttype aan zoekwoorden.
Jan-Willem heeft een gestructureerd systeem ontwikkeld voor het optimaliseren van SEO-processen:
- Database Creatie: Maak een database met trefwoorden en de URL’s die hiervoor ranken. Hierbij kunnen tools zoals BeautifulSoup of Selenium ingezet worden.
- Pagina Scraping en Classificatie: Scrape de inhoud van de pagina’s en classificeer de URL’s op basis van contenttype.
- Identificatie van Best Scorende Contenttype: Bepaal welk type content het beste scoort voor de gegeven trefwoorden.
- Vervolgacties Bepalen: Stel vervolgacties op, gebaseerd op waargenomen dalingen of toenames in rankings.
- Herhaalde Analyse: Voer deze analyse tweewekelijks en maandelijks uit voor continue optimalisatie.
Het scrapen van de pagina’s wordt niet uitgevoerd met een standaard LLM (Large Language Model), maar met een LLM die specifiek is getraind voor het classificeren van inhoud. Stap-voor-stap instructies voor deze aanpak zijn te vinden op https://notprovided.eu/intent.
Belangrijkste learnings van de presentatie:
- Achterhaalde Standaard Zoekintentie: De traditionele categorieën van zoekintentie (zoals informatief, navigatie, transactioneel en commercieel onderzoek) zijn niet langer voldoende. Ze bieden geen inzicht in het type content dat Google aanbeveelt.
- Veranderingen in Gebruikersintentie: De manier waarop Google zoekopdrachten interpreteert, evolueert voortdurend. Deze veranderingen beïnvloeden de zichtbaarheid van websites in zoekresultaten.
- In Kaart Brengen van Veranderingen: Door gebruik te maken van een speciaal getraind Large Language Model (LLM) is het mogelijk om deze verschuivingen in zoekintentie te detecteren. Dit biedt waardevolle inzichten om de SEO-strategie dienovereenkomstig aan te passen.

